
7 Predictive Analytics-Methoden im Marketing
Dank Predictive Analytics wissen Marketingexperten heute schon vorher, wie Kunden reagieren, und können so Umsatz- und Gewinnpotentiale besser ausschöpfen. Predictive Analytics, oft auch als Predictive Marketing bezeichnet, beschreiben Datenanalysen, die Unternehmen dabei helfen, aus Big Data relevante Insights über zukünftiges Kundenverhalten abzuleiten. Marketern stehen hierbei eine Vielzahl an verschiedenen Methoden zur Verfügung, die unterschiedliche Informationen liefern. Gängige Fragestellungen, die mithilfe von Predictive Analytics-Methoden im Marketing beantwortet werden können, sind z.B.:
- Welche Produkte biete ich meinen Kunden als nächstes an?
- Welchen Umsatz wird ein Kunde generieren?
- Wie hoch ist die Kaufwahrscheinlichkeit eines Kunden Y für Produkt X
Um diese und viele andere Fragen zu beantworten stellen wir im Folgenden sieben Predictive-Analytics-Methoden vor, die Sie als Marketer kennen sollten.
1. Profiling im Marketing
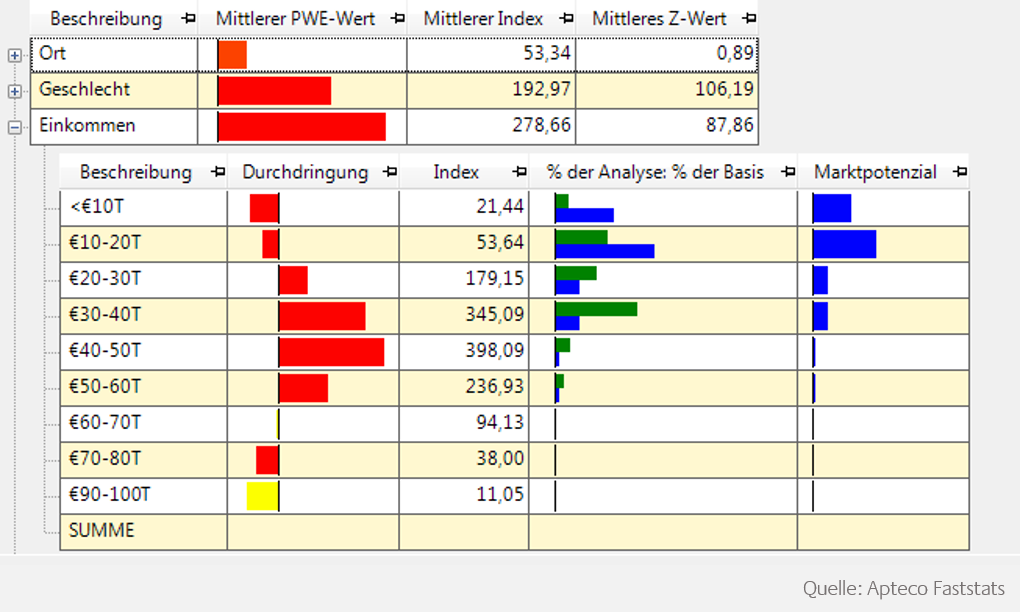
Profiling dient der Beschreibung von Personen anhand von Eigenschaften oder Verhalten. Beispielsweise kann es verwendet werden, um das typische Verhalten eines Topkunden zu charakterisieren.
Dabei wird die zu analysierende Zielgruppe mit einer Grundgesamtheit verglichen. Dazu definieren Sie mehrere Variablen, die im Modell betrachtet werden sollen. Das Profil zeigt Ihnen die Durchdringung dieser Variablen für Ihre Analysemenge auf. Anhand des Histogramms sehen Sie, welche Ausprägungen über- oder unterrepräsentiert sind.
2. Assoziationsanalyse (Warenkorbanalyse)
Die Assoziationsanalyse sucht nach Mustern, bei denen ein Ereignis mit einem anderen Ereignis verbunden ist. Ein häufig verwendetes Beispiel ist der Warenkorb. Er beinhaltet den in einem definierten Zeitraum gekauften Mix von Produkten/Marken. Die Warenkorbanalyse ermittelt dabei die Kaufwahrscheinlichkeit für jedes der im Warenkorb enthaltenen Produkte mit dem Ziel, Muster und Regeln im Kaufverhalten aufzudecken.
Ein typisches Anwendungsfeld ist die Identifikation von Zusammenhängen beim Kauf, um darauf gezielt mit Werbemaßnahmen zu reagieren, z. B. durch Cross-Selling.
3. Logistische Regression
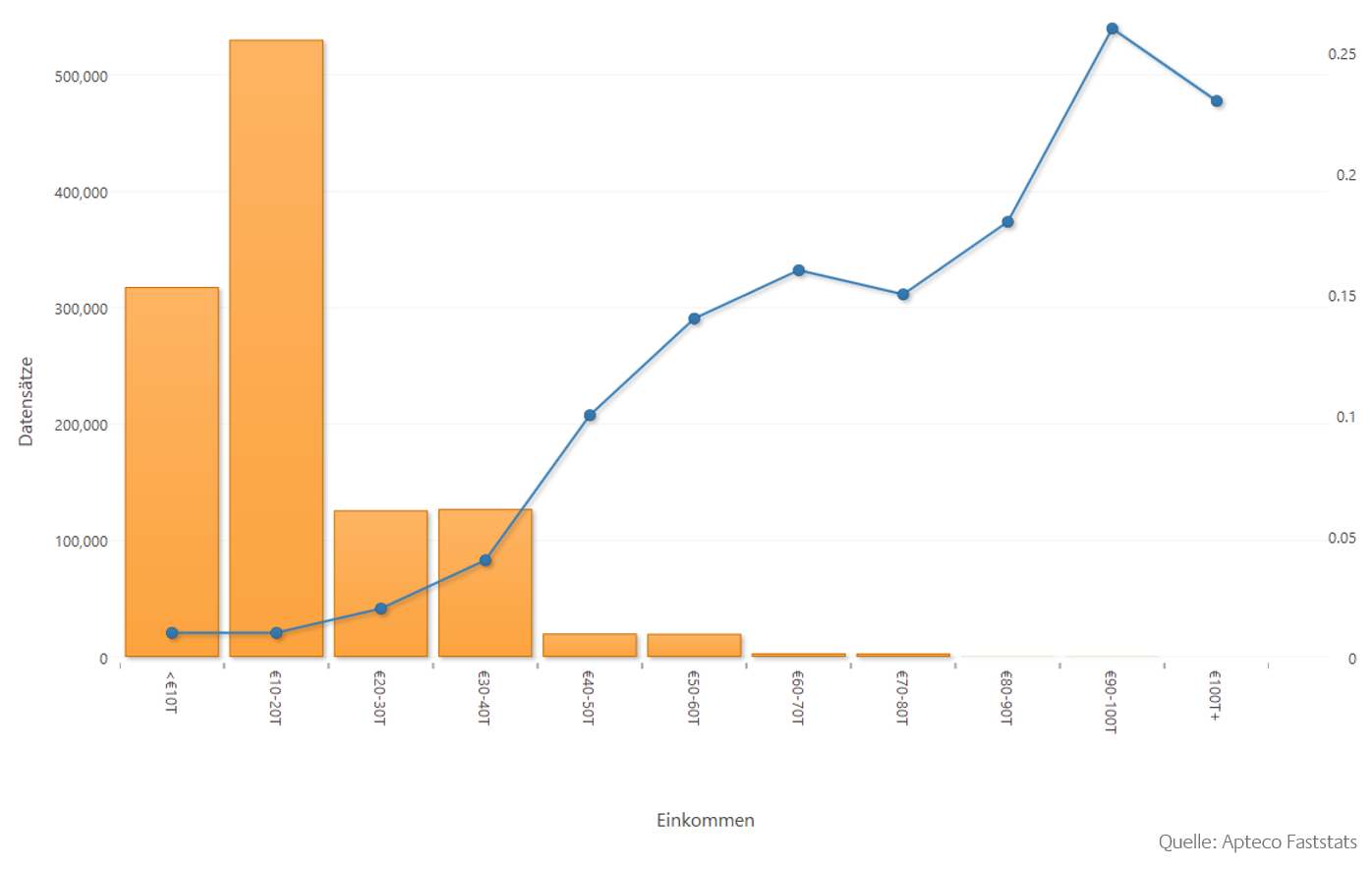
Mit logistischer Regression kann bestimmt werden, mit welcher Erfolgswahrscheinlichkeit ein Ereignis von bestimmten Variablen abhängt. So können beispielsweise Conversion-Prognosen erstellt werden. Eine typische Fragestellung: Mit welcher Wahrscheinlichkeit kauft ein Kunde ein bestimmtes Produkt?
Zur Erstellung des statistischen Modells müssen Trainingsdaten präpariert und Vorhersagevariablen festgelegt werden. Als Ergebnis erhält man eine Reihe von Koeffizienten. Je signifikanter diese sind, desto aussagekräftiger ist die entsprechende Eigenschaft für das Eintreten des Ereignisses.
Das Diagramm zeigt die Wahrscheinlichkeit, dass eine Person einen Urlaub bucht in Abhängigkeit vom Einkommen.
4. Entscheidungsbaumanalyse
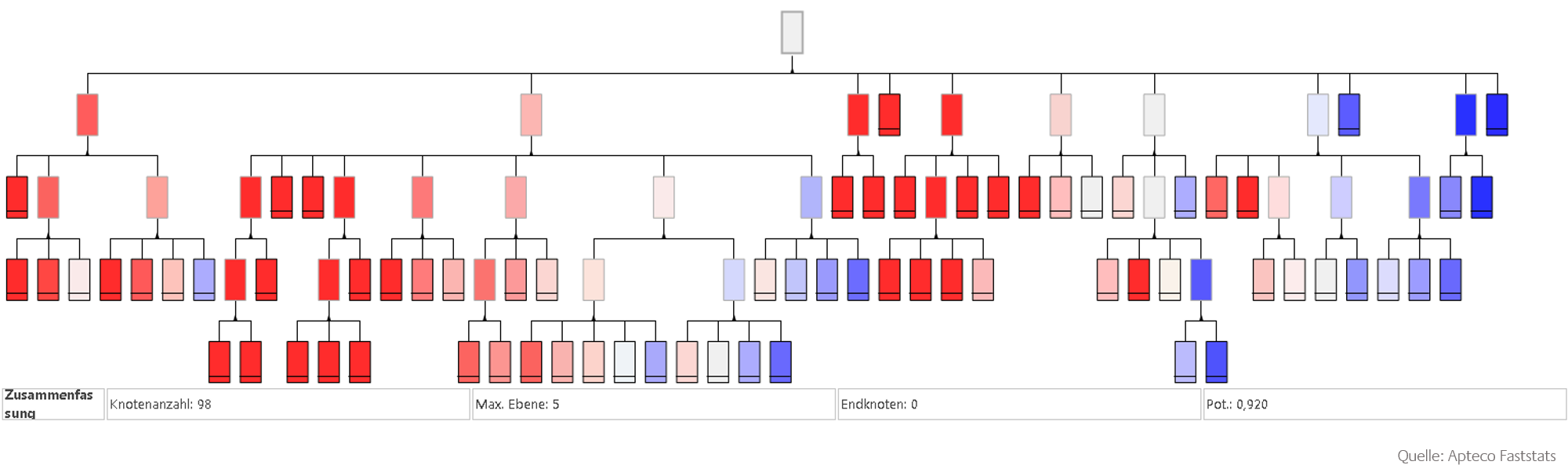
Ein Entscheidungsbaum präsentiert Entscheidungsregeln, anhand derer Daten klassifiziert und übersichtlich grafisch dargestellt werden. Bei der Entscheidungsbaumanalyse erfolgt die statistische Klassifizierung durch die sukzessive Aufspaltung einer Analysemenge, sodass sich in den daraus entstehenden Untermengen homogenere Gruppen hinsichtlich der Klassifikationsvariablen wiederfinden. Darauf basierend wird anschließend ein statistisches Modell entwickelt, das bei der Klassifizierung neuer Daten hilft. Je intensiver das Rot in der Baumstruktur desto besser ist dieser Knoten geeignet, die zu analysierende Zielgruppe zu beschreiben.
5. Best Next Offer
Best Next Offer (häufig auch Next Best Offer genannt, wir finden jedoch, dass Best Next Offer präziser beschreibt, was diese Methode tut) ordnet jedem Kunden die Produkte zu, die er am wahrscheinlichsten kaufen wird. Genau diese Produkte werden dem Kunden dann beispielsweise bei seinem nächsten Besuch im Onlineshop angezeigt. Es ist inzwischen bewiesen, dass so deutlich mehr Umsatz erzielt wird als bei einer zufällig ausgewählten Produktanzeige.
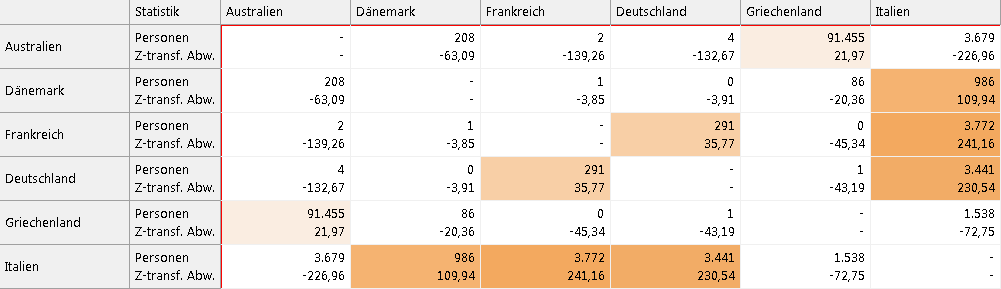
Als Voraussetzung wird dazu die Kaufhistorie der Kunden benötigt. Bei der Berechnung kommen zwei Parameter hinzu, welche die allgemeine Beliebtheit der Produktkombination (Popularität) und die statistische Signifikanz der Produktkombination (Propensität) beschreiben. Dieses Verhältnis kann je nach Anforderung unterschiedlich gewichtet werden. In einem Cube lässt sich darstellen, welche Kombinationen (z.B. Italien/Frankreich) besonders signifikant sind.
6. Clusteranalyse
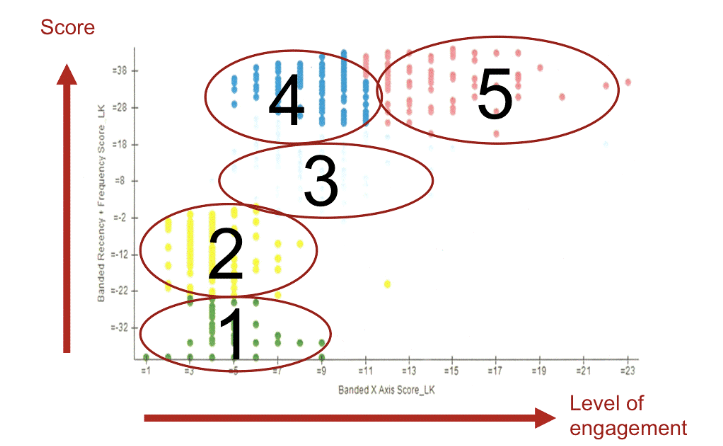
Die Clusteranalyse ist ein Gruppenbildungsverfahren, das nach Mustern in Daten sucht − mit dem Ziel, aus einer heterogenen Gesamtheit homogene Teilmengen zu identifizieren. Dabei sollen die Unterschiede zwischen den einzelnen Gruppen (= Cluster) möglichst deutlich und die Unterschiede innerhalb einer Gruppe möglichst gering ausfallen. Dies gelingt mittels Berechnung von Proximitätsmaßen (z.B. Euklidische Distanz) und der anschließenden Zusammenfassung von Objekten zu Gruppen.
Abhängig von den gewählten Merkmalen können Marketer mit der Clusteranalyse ganz unterschiedliche Aufgabenstellungen angehen. Ein Produkt für eine bestimmte Zielgruppe kann entwickelt oder Persönlichkeitstypen können gefunden werden. Dazu ist es notwendig, die Existenz, die Größe und eine detaillierte Charakterisierung dieser Zielgruppen zu kennen. Das Beispiel in der Abbildung zeigt, wie sich fünf Cluster in Abhängigkeit zweier Variablen bilden lassen.
7. Lineare Regression
Allgemein versucht man mit der linearen Regression, den numerischen Wert einer beobachteten abhängigen Variablen vorherzusagen oder zu schätzen, z.B. den Jahresumsatz pro Kunde, indem ein funktionaler Zusammenhang zwischen mehreren Größen hergestellt wird. Aus den erlangten Kenntnissen können dann zukünftige Prognosen bzw. Trends abgeleitet werden.
Die Ermittlung der Regressionsfunktion besagt allerdings noch nicht, ob es sich um einen signifikanten ermittelten Zusammenhang handelt. Die Signifikanz der Regression ist durch einen so genannten F-Test zu verifizieren.
Infografik 7 Predictive Analytics Methoden im Marketing
Unsere Infografik liefert Ihnen einen schnellen Überblick über die 7 genannten Predictive Analytics Methoden im Marketing.
