Modelling und Scoring von Kunden: Verbessern Sie Ihr Targeting in 4 Schritten
28 Juni 2017 | von Ray Kirk
Mit diesen 4 einfachen Modelling- und Scoring-Schritten, verbessern Sie die Genauigkeit und Effektivität Ihres Marketings.
Verbessern Sie die Effektivität Ihres Marketings
Sie erfahren, warum Modelling und Scoring von Kunden wichtig ist, wie Sie es einsetzen können, und Sie lernen 4 einfache Modelling- und Scoring-Techniken kennen.
Warum überhaupt?
Viele Unternehmen nutzen Direct Marketing (z.B. Post-Mailings, Telemarketing, E-Mail-Marketing), um potenzielle Kunden („Prospects“) über Produkte und Services zu informieren. Häufig können diese Unternehmen dazu auf große Datenbanken zurückgreifen. Auf den ersten Blick ein Vorteil, aber gleichzeitig ist es sehr teuer, alle potenziellen Kunden anzusprechen und manchmal eher kontraproduktiv, nämlich dann, wenn Interessenten durch irrelevante Werbung vergrault werden. Modelling und Scoring von Kunden, ermöglicht es den Firmen, diejenigen Nachrichten, Produkte und Services zu identifizieren, die zu jedem einzelnen Kunden am besten passen. Außerdem können sie feststellen, wie hoch die Kauf-Wahrscheinlichkeit ist. Diese Segmentierung erlaubt passgenaues Targeting der Kunden mit relevanten Marketingbotschaften.
Wie kann Modelling und Scoring genutzt werden?
Modelling von Kunden kann genutzt werden, um das Targeting in den folgenden Situationen zu verbessern:
• Ein allgemeines Ziel ist es, Direct Marketing Aktivitäten an diejenigen Kunden zu richten, die am ehesten Ihr Produkt oder Ihren Service in Anspruch nehmen („Responders“). Ziel könnte es sein, einerseits neue Interessenten zu identifizieren (die noch keine Kunden sind), oder zusätzlichen Umsatz von Bestandskunden zu generieren.
• In einer anderen Situation, kann Modelling und Scoring dazu genutzt werden vorauszusagen, wie wahrscheinlich es ist, dass ein Neukunde einen hohen Life Time Value aufweisen wird. Wenn Sie diese Personen identifizieren, können Sie sicherstellen, dass diese Kunden spezielle, präzise und passgenaue Kommunikationen erhalten.
• Alternativ wollen Sie vielleicht herausfinden, welche Kunden am wahrscheinlichsten abwandern werden. Mithilfe dieser Information, können Sie diese Personen frühzeitig kontaktieren und eine Abwanderung verhindern, indem Sie einen Kauf incentivieren.
In all diesen Situationen (und vielen anderen!) wird ein statistisches Modell genutzt, das bestimmte Datensätze scort, um diejenigen Kunden zu identifizieren, die für eine Marketingaktivität besonders geeignet sein werden (Zielgruppe).
Wie erstellt man ein statistisches Modell?
Wenn es um Modelling geht, arbeiten Sie in jedem Fall mit einer Kundendatenbank, in der eine Teilmenge der Kunden als „Zielmarkt“ identifiziert wurde. In den obenstehenden Beispielen, könnten dies, Reagierer auf eine vorherige Kampagne, bestehende Kunden mit hohem Life Time Value oder bereits abgewanderte Kunden sein.
Der Modelling-Prozess vergleicht dann die Zielgruppe mit dem gesamten Datenbestand, um Charakteristiken zu identifizieren, die diese voneinander differenzieren. Ein Ergebnis könnte beispielsweise sein, dass die Zielgruppe ein bestimmtes Alter oder Einkommen aufweist oder Nutzer eines anderen Produktes ist.
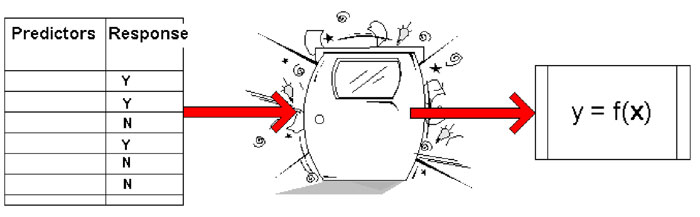
Wie nutzt man ein Modell, um einen Score zu erstellen?
Das Endergebnis eines Modelling-Prozesses liegt darin, einen Score für alle Personen in der Datenbank zu generieren. Personen erhalten einen hohen Score, wenn sie gleiche Charakteristiken aufweisen, die typisch für die Zielgruppe sind.
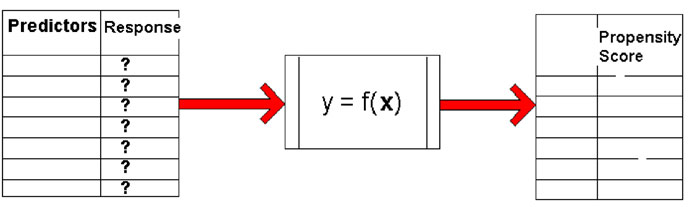
Die Erstellung eines Modells identifiziert Schlüsselmerkmale (Predictors) der Zielgruppe. Dieses basiert auf der Datenanalyse von bekannten Antworten (Response) und resultiert in einer Formel oder einer Reihe von Regeln. Dieses Modell wird anschließend auf Daten mit den gleichen Prädikator-Variablen angewendet, bei denen die Antworten aber unbekannt sind. Daraus entsteht eine Reihe von Propensitäten-Scores (Propensity Score). Diese Scores können dazu genutzt werden, Kunden zu selektieren, die den Reagierern aus der ursprünglichen Zielgruppe am ähnlichsten sind.
4 einfache Modelling Schritte
Die wichtigsten Schritte sind:
1. Identifizieren der Business-Frage
Der erste Schritt beim Modelling von Kunden sollte die Frage danach sein, was genau sie mithilfe des Modells in Erfahrung bringen wollen (Dies nennt man auch Response-Variable, unabhängige Variable oder Ziel-Variable). Das kann einfach sein, wie beispielsweise das Identifizieren aller Datensätze, die als Kunde markiert sind und selbstverständlich auch deutlich komplexer, zum Beispiel auf Basis von Produkt-Upgrades oder Life-Time-Value-Kriterien.
Bitte beachten Sie: In diesem Fall sprechen wir von Modelling von Kunden/Nicht-Kunden. Hierbei handelt es sich lediglich um ein Beispiel. Im B2B-Umfeld kann der Bezug auf Konsumenten beispielsweise auf Unternehmen ausgeweitet werden.
2. Erforschen und vorbereiten der Daten
Um ein Modell zu erstellen, benötigen wir sowohl Datensatz-Informationen von Kunden, als auch von Nicht-Kunden. Kunden können Unternehmen im B2B-Umfeld oder eben individuelle Konsumenten sein. Potenzielle Variablen zur Vorhersage für Unternehmen könnten geografische Lage, Unternehmensgröße, Klassifizierung oder Umsatz sein. Für individuelle Konsumenten wären dies beispielsweise Alter, Einkommen, Haushaltsgröße oder Wohnort. Gemeinsam mit einem Response-Indikator (z.B. Y für Kunden, N für Nicht-Kunden) bildet dies das „training set““.
Welche Variablen genutzt werden, sollte gut überlegt sein. In manchen Fällen müssen Sie sich sogar neue, aussagekräftigere Variablen von bestehenden ableiten. Beispielsweise, wenn Sie die Gesamtausgaben der Kunden im letzten Jahr berechnen oder das Verhältnis zwischen den diesjährigen und den letztjährigen Ausgaben berechnen wollen.
3. Erstellen des Modells
Diese Informationen fließen in den Erstellungsprozess des Modells ein. Daraus resultiert wiederum eine Formel bzw. eine Reihe an Regeln, die dazu genutzt wird, ähnliche Kunden zu identifizieren. Es gibt eine große Vielfalt an Erstellungstechniken von Modellen, aber auf dem einfachsten Level beschreibt die Modellformel im Grunde die wichtigsten Merkmale, die Ihre Kunden von dem gesamten Datenbestand unterscheiden. So kann das Modell Interessenten vorhersagen, indem es prüft, ob die gleichen charakteristischen Merkmale vorhanden sind.
Das Erstellen von Modellen beinhaltet auch das Validieren von alternativen Modellen, indem sie auf Datenbestände mit bekanntem Kunden-Status angewendet werden, und anschließend gemessen wird, wie erfolgreich das Modell bekannte Kunden klassifiziert. Ein gutes Modell wird hauptsächlich hohe Scores für bekannte Kunden für die Zielgruppe ausgeben. Um zu verhindern, dass das Modell direkt mit den Daten getestet wird, auf denen es basiert, wird für gewöhnlich ein Teil der Daten ausgeschlossen, um diese für Testzwecke nutzen zu können.
4. Scoring der Datenbank und Selektion der potenziellen Kunden
Ist ein Modell einmal erstellt, wird es auf den Datenbestand angewendet und für alle Datensätze ein Score generiert. Generell werden diejenigen mit einem hohen Score selektiert (d.h. die Personen, die am wahrscheinlichsten reagieren oder Kunden mit hohem Wert sind).
Es sollte gut überlegt sein, wo die Grenze gesetzt wird und wie viele Kunden mit hohem Score letztendlich selektiert werden sollen. Die Entscheidung kann basierend auf finanziellen Gesichtspunkten getroffen werden: Zum Beispiel, wenn der erwartete Umsatz die Kosten eines Mailings ausgleicht. Oder basierend auf anderen Businessfaktoren. Modelling und Scoring von Kunden erlaubt Ihnen außerdem tiefere Einblicke, wie Kunden mit Ihnen entlang ihrer Customer Journey interagieren.
Sie wollen sich weiter mit diesem Thema beschäftigen? Dann erfahren Sie jetzt, wie Sie mit Predictive Analytics, den nächsten Kauf Ihres Kunden vorhersagen können.